Co-authored by Eran Sher
“Program testing can be used to show the presence of bugs, but never to show their absence!” – Edsger W. Dijkstra
As more and more companies progress towards leaner and frequent rapid releases. They increasingly invest in test automation to preserve a healthy culture since it’s crucial for Continuous Delivery. Despite all the effort, I still hear horror stories about ongoing stability issues, elusive bugs carried to users, and unexpected behavior in production environments, even with full blown multi-level test suites running within the pipeline process. The realization I came to is that there’s a major blind spot in software quality which is consistently overlooked. That blind spot is test quality.
WTF is Test Quality?
We invest a lot in code quality. From static-analysis to linters, code reviews, code coverage and of course, automated tests. All of these measures, especially testing, have a singular purpose: Improve and maintain code quality. While each works and contributes to their domain, the line of defense still has a weak link – your tests.
If code contains bugs is an axiom, and we know that tests are also code, then tests contains bugs must be true as well. The question that remains is: who watches the watchman?
Release Software Faster | Download >>
Enter Mutation Testing
Mutation Testing is a fault–based software testing technique that has been widely studied for over three decades and the literature generated around the topic has contributed approaches, tools, developments and empirical results for its implementation. It has remained for the most part overlooked by the industry, which I find somewhat baffling after examining and grasping its added value.
The concept behind mutation testing is quite simple. Faults (or mutations) are automatically seeded into your code and then your tests are executed. If your tests failed then the mutation was killed if your tests passed then the mutation survived. The quality of your tests can be gauged from the percentage of mutations killed. As such Test Quality enables you to detect whether each statement in your code has been meaningfully tested. The mutation testing “kill-rate” metric is the gold standard against which all other types of coverage must be measured – Software Quality = Code Quality + Test Quality
Think about it this way, it’s no different from hiring a white-hat hacker to find exploits in your app so you can fix them before any harm is caused. Only in this case, you’re using mutations to find exploits in your tests before they progress. Another example of this approach (Bebugging/fault-injection/chaos-engineering) is Netflix’s Chaos-monkey that randomly terminates backend objects, specifically on AWS & Kubernetes, and tests the robustness of the system and its ability to auto-heal and recover, or at least incentivizes developers to build resilient services.
Getting Started with Mutation Testing
A good POC project should have a fair amount of unit-tests, the more, the merrier, and at least 50% code coverage. Why a 50% minimum you ask? So that there will be enough raw material for the mutation test to work with.
Next – install your framework:
- Java
- Framework: pitest.org
- Example: https://github.com/klynch/pit-example
- Javascript
- Framework: stryker-mutator.github.io
- Example: https://github.com/Sealights/israeli-queue
- Python
- Framework: cosmic-ray.readthedocs.io
Configure the framework with your code and test files, then run it.
Now pay attention to your mutation score (kill-rate).
Let’s take a look at the javascript example from above:

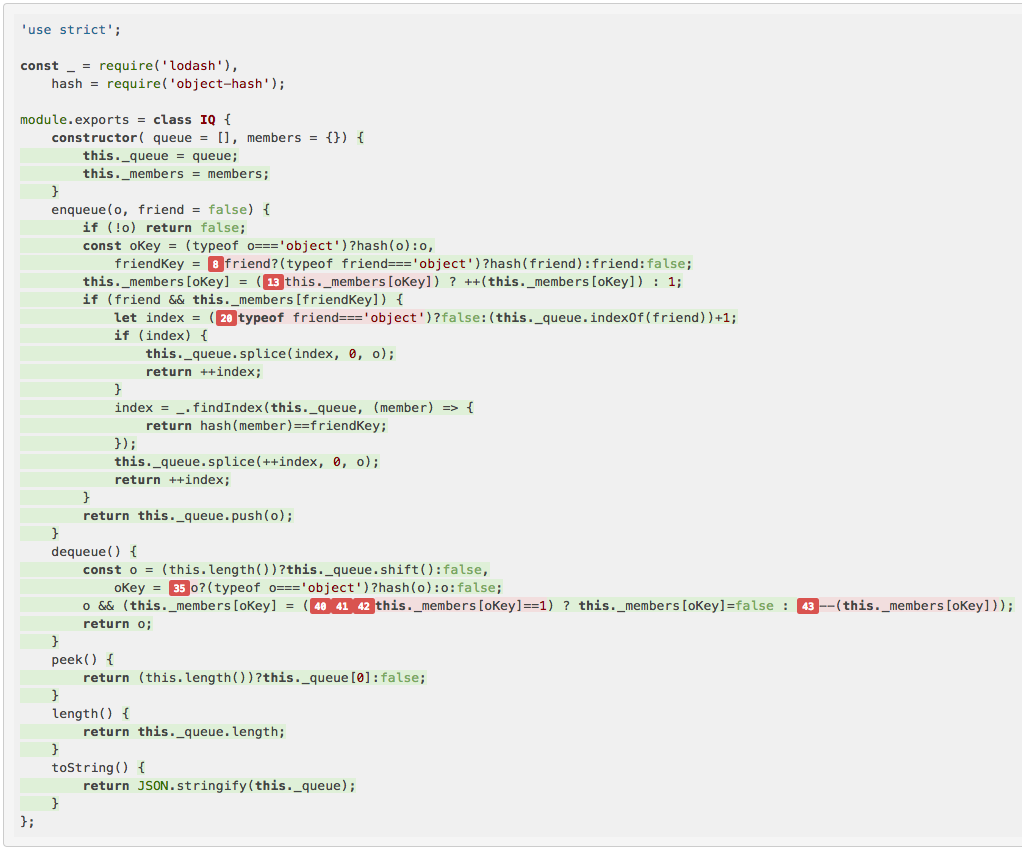
Use your tool’s code drill down report to see which mutations survived line-by-line. Now you can see cases that you missed in your tests.
From here on out it’s about improving your tests and killing more mutations, but don’t go on a killing spree since some cases will not be worthwhile to pursue. Any score higher than 80% usually qualifies since our time is valuable. According to the 80-20 rule, it doesn’t make sense to invest 80% of our efforts to improve test quality in order lock down the last 20% corner cases in our mutation score.
In this example above (based on stryker) note the flagged code, these are statements that mutated and survived (8 out of 49). Clicking on each flag will reveal the survived mutation. Let’s focus on the statement with three survived mutants and collapse it:

We can see that the mutations that survived are found only within conditional instructions. This suggests that some inner logic related to the conditional statements was not validated in these tests.
Sidenote: the example above is written in node.js, but stryker-mutator has multiple plugin support for browser compatible UI test frameworks such as mocha, jasmine, karma etc.
Integrating with Your Continuous Deployment Pipeline
Once configured correctly, your frameworks can perform the entire process automatically meaning that it can run within your CD pipeline easily and interact with your dashboard accordingly. I recommend running it alongside your functional/ integration test suite since mutation testing generates many permutations per line and needs time and resources to complete. You can also set a minimum mutations threshold allowed to survive before failing the build.
Java/ Jenkins people for note, you can go ahead and grab your pitest Jenkins plugin here.
Quality Dashboard
As part of CD pipeline, you are probably using a quality dashboard for your apps. You can wire your mutation score as a custom metric into your dashboard via the SeaLights API (If you aren’t using a dashboard then now’s a very good time to start) and utilize weighted averages on your other existing quality metrics such as coverage, quality-holes, mutation-test score. The result is a normalized number between (0,1) a nice heuristic that gives a great estimation of overall product software quality.
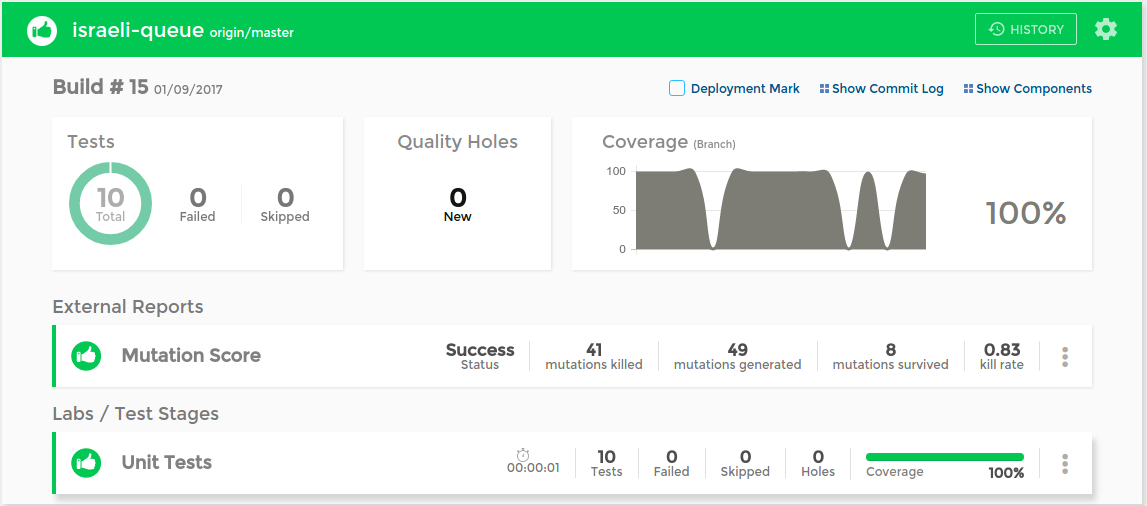
The SeaLights dashboard with the mutation kill rate score rendered into it.


The threshold configuration setup including failed tests, coverage, trends and mutation custom metric.
Summary
Managing quality is hard so disregarding test quality doesn’t make sense. We need to emphasize test quality as a metric, and power up our dashboards with high-quality coverage that can better reassure feature owners when rolling out.
Happy hunting!