The software development landscape is constantly changing. Staying on the top of your game requires a perpetual search for new technologies and methodologies that can help the team be better. After over 20 years in software development, I know that each team has its own pace, strengths, and weaknesses. The agile process encourages us to constantly improve, which is why you complete a retrospective at the end of each sprint/release; to preserve what went well in the sprint/release and to spot what needs to be improved next time.
The availability of data provides another valuable resource for self and team improvement and also gives you the ability to compare your work with other similar teams. The trick here is to make sure you understand the value of the external data and look at only what is relevant to you. You should recognize that some of the comparison data can be actionable for the team tomorrow, while other of the comparison data can just indicate areas you should examine further.
In this blog, I will share information from 3 interesting papers that present the main challenges of software teams, both from the perspective of managers, as well as developers. By understanding other teams’ challenges, you might discover similar challenges in your own software development process. I will provide you with snippets of the data and my opinion, but you can learn even more by going over the full reports (an important aspect is understanding the survey audience and methodology). There is a lot of data in these reports, and I’m just touching the tip of the iceberg.
The three papers I’m referring to are:
- State of Software Development 2018, by Coding Sans
- 2018 Global Developer Report, by GitLab
- The State of Developer Ecosystem in 2018, by JetBraines
Release Frequency – An Indicator for the Challenge Scale
The organization decides on the desired software release frequency based on market demand and customers’ expectations. The quicker software is released, the better the team should be with its process, tools and automation level. From the GitLab report, we witness that the release frequency is high and therefore, driving more complex challenges.
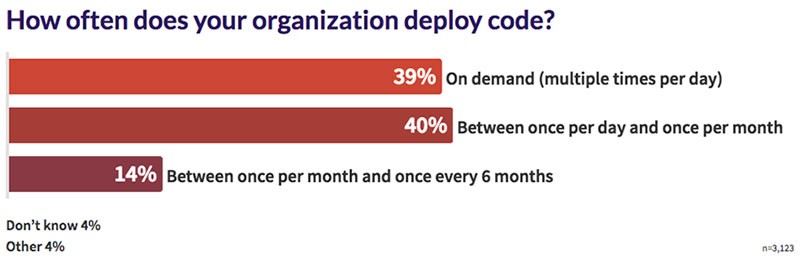
The trend of increasing the release frequency from past years continues to grow. It is obvious that the amount of data created throughout the software pipeline is huge and in order to use it in a meaningful manner, teams should adopt a proper method to collect and analyze the data.
What are Software Engineers’ Biggest Challenges?
The path for quicker release lies with the removal of barriers. In the Coding Sans survey, they asked what is the biggest challenge the respondents face in software development. The two main reasons reported were team capacity and the difficulties with hiring talents.
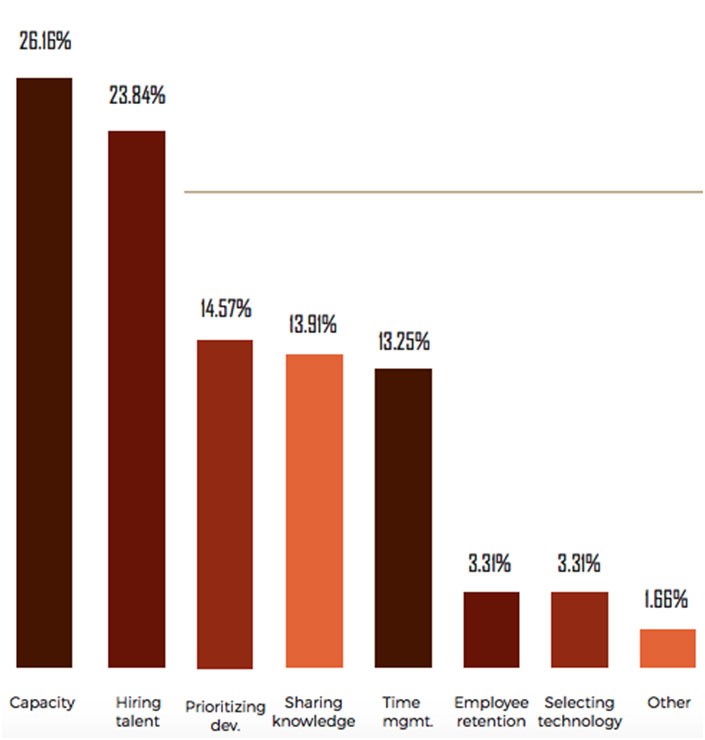
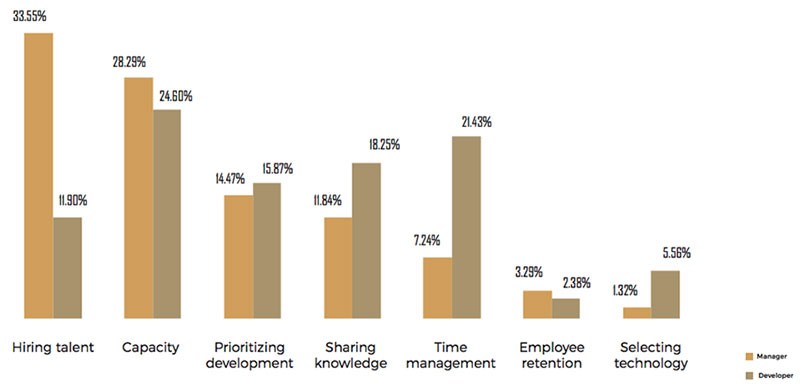
When the answers are divided between developers and managers we find a slight difference: managers are more concerned with the hiring and developers are more concerned with capacity.
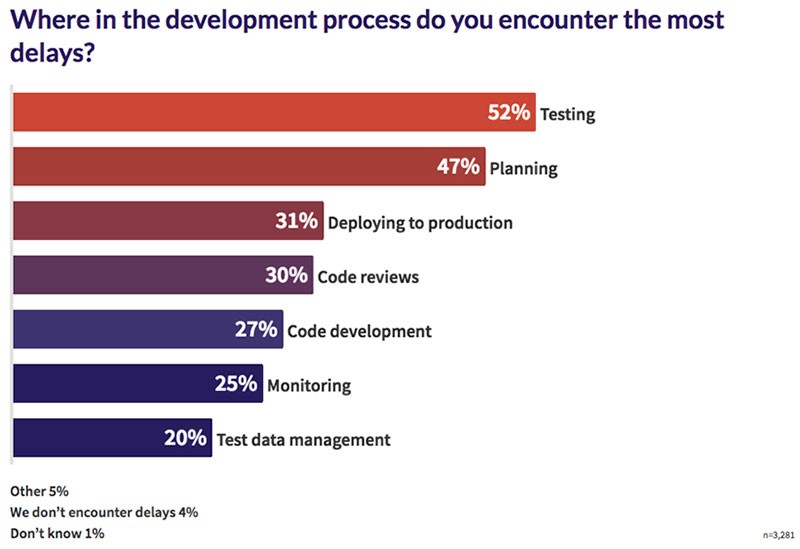
I don’t have any good suggestions for the hiring challenge, but there are some good methods to solve the issue of capacity. In the graph below from GitLab we can see what teams feel are the major barriers to meet the desired capacity. Testing is listed as the number one reason for delays. If teams are able to identify the important quality activities that they should invest in, it can save a lot of time, improve capacity, and reduce delays. The trend today is that many of the tests are written by the developer (TDD but also API and End to End tests), and in many cases, due to lack of visibility there is a lot of overlapping with the tests. Proper planning can contribute to the overall effort.
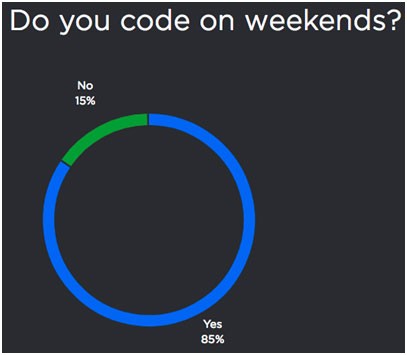
Another method for the capacity issue is spending more time coding, like on the weekend. I don’t think this is a good practice and we need to find the right balance between work and leisure. However, as you can see from the JetBrains graph, many think different than me.
If you’ll take a few minutes to learn more about Sealights you will see that we believe that in today’s age engineering teams should have the capabilities to plan their work in an efficient manner based on data from the entire software pipeline. This is exactly what we are doing with quality intelligence technology and I believe the different data points from the surveys are aligned with this view.